Проекции
Введение
ClickHouse предлагает различные механизмы ускорения выполнения аналитических запросов по большим объёмам данных в сценариях реального времени. Один из таких механизмов — использование Projections. Projections помогают оптимизировать запросы за счёт переупорядочивания данных по интересующим атрибутам. Это может быть:
- Полное переупорядочивание данных
- Подмножество исходной таблицы с иным порядком строк
- Предварительно вычислённая агрегация (аналогично материализованному представлению), но с порядком, согласованным с этой агрегацией.
Как работают Projections?
Практически Projection можно рассматривать как дополнительную, скрытую таблицу к исходной таблице. Проекция может иметь иной порядок строк и, следовательно, другой первичный индекс по сравнению с исходной таблицей, а также может автоматически и по мере вставки данных предварительно вычислять агрегированные значения. В результате использование Projections дает два «рычага настройки» для ускорения выполнения запросов:
- Корректное использование первичных индексов
- Предварительное вычисление агрегатов
Projections в некотором смысле похожи на Materialized Views, которые также позволяют иметь несколько порядков строк и предварительно вычислять агрегации во время вставки. Projections автоматически обновляются и поддерживаются в актуальном состоянии и синхронизированными с исходной таблицей, в отличие от Materialized Views, которые обновляются явно. Когда запрос направлен к исходной таблице, ClickHouse автоматически сэмплирует первичные ключи и выбирает таблицу, которая может сгенерировать тот же корректный результат, но требует чтения наименьшего объема данных, как показано на рисунке ниже:
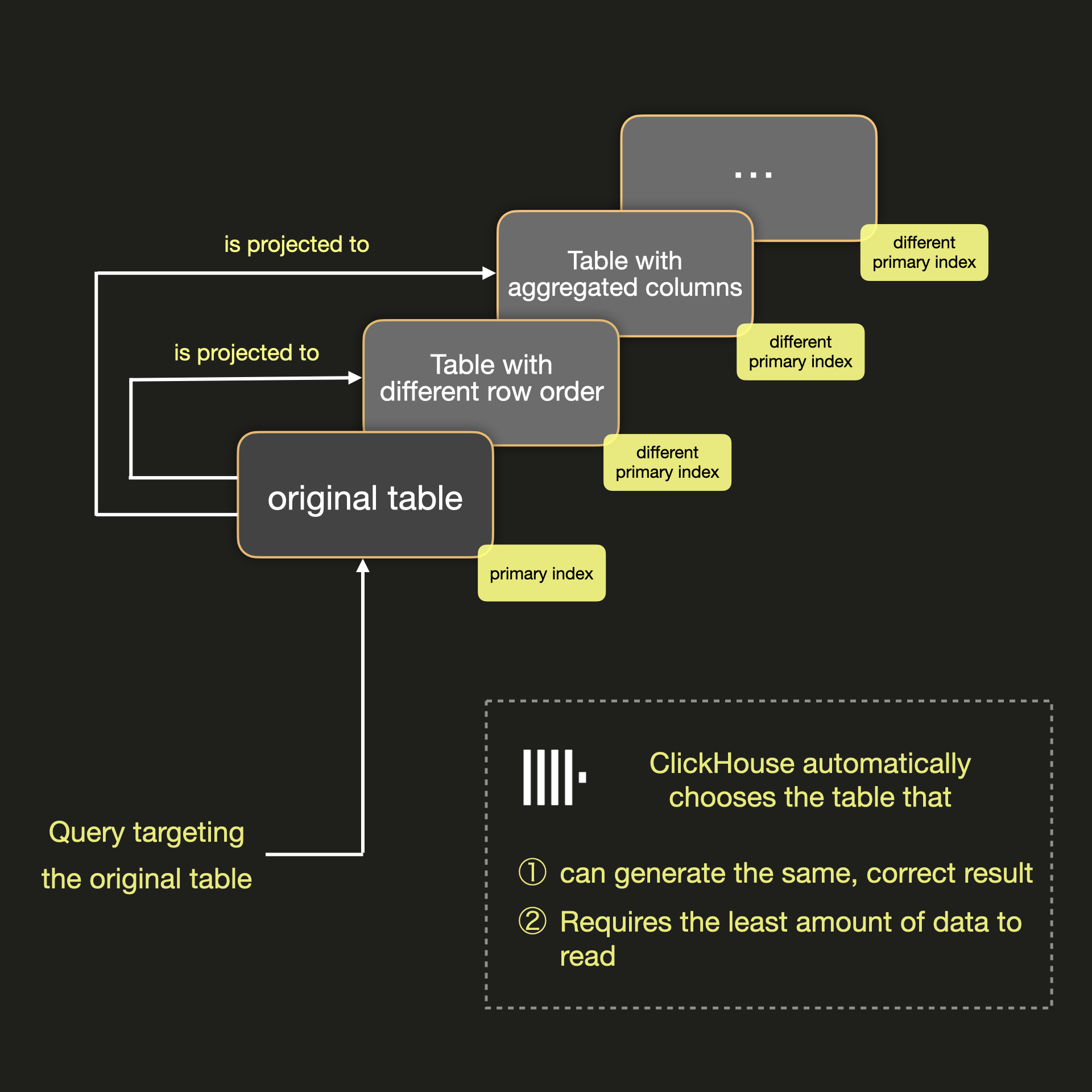
Более умное хранение с _part_offset
Начиная с версии 25.5, ClickHouse поддерживает виртуальный столбец _part_offset
в проекциях, который предлагает новый способ определения проекции.
Теперь есть два способа определить проекцию:
-
Хранить полные столбцы (исходное поведение): проекция содержит полные данные и может читаться напрямую, обеспечивая более высокую производительность, когда фильтры соответствуют порядку сортировки проекции.
-
Хранить только ключ сортировки +
_part_offset: проекция работает как индекс. ClickHouse использует первичный индекс проекции для поиска соответствующих строк, но читает фактические данные из базовой таблицы. Это снижает накладные расходы на хранение ценой немного большего объема операций ввода-вывода во время выполнения запроса.
Указанные подходы также можно комбинировать, храня часть столбцов в проекции, а
остальные — косвенно через _part_offset.
Когда использовать проекции?
Проекции являются привлекательной возможностью для новых пользователей, поскольку они автоматически поддерживаются по мере вставки данных. Кроме того, запросы могут отправляться просто к одной таблице, где проекции при возможности используются для ускорения времени отклика.
В отличие от этого, при использовании материализованных представлений пользователю необходимо выбирать подходящую оптимизированную целевую таблицу или переписывать запрос в зависимости от фильтров. Это создает большую нагрузку на пользовательские приложения и увеличивает сложность на стороне клиента.
Несмотря на эти преимущества, у проекций есть ряд встроенных ограничений, о которых пользователям следует знать, поэтому их следует использовать избирательно.
- Проекции не позволяют использовать разные TTL для исходной таблицы и (скрытой) целевой таблицы, тогда как материализованные представления допускают разные TTL.
- Легковесные операции обновления и удаления не поддерживаются для таблиц с проекциями.
- Материализованные представления можно выстраивать в цепочки: целевая таблица одного материализованного представления может быть исходной таблицей для другого материализованного представления и так далее. Это невозможно для проекций.
- Проекции не поддерживают
JOIN, тогда как материализованные представления поддерживают. - Проекции не поддерживают фильтры (клауза
WHERE), тогда как материализованные представления поддерживают.
Мы рекомендуем использовать проекции, когда:
- Требуется полная переупорядоченная организация данных. Хотя выражение в
проекции теоретически может использовать
GROUP BY, материализованные представления более эффективны для поддержки агрегатов. Оптимизатор запросов также с большей вероятностью будет использовать проекции, выполняющие простое переупорядочивание, то естьSELECT * ORDER BY x. Пользователи могут выбрать подмножество столбцов в этом выражении, чтобы уменьшить объем хранимых данных. - Пользователи готовы к возможному увеличению объема хранимых данных и накладным расходам на двойную запись данных. Протестируйте влияние на скорость вставки и оцените накладные расходы на хранение.
Примеры
Фильтрация по столбцам, которые не входят в первичный ключ
В этом примере мы покажем, как добавить проекцию к таблице. Мы также рассмотрим, как можно использовать проекцию для ускорения запросов, которые фильтруют по столбцам, не входящим в первичный ключ таблицы.
В этом примере мы будем использовать набор данных New York Taxi Data,
доступный на sql.clickhouse.com, который упорядочен
по pickup_datetime.
Напишем простой запрос, чтобы найти все идентификаторы поездок, в которых пассажиры дали водителю чаевые свыше 200 $:
Обратите внимание, что поскольку мы фильтруем по tip_amount, который не участвует в ORDER BY, ClickHouse
вынужден выполнить полное сканирование таблицы. Ускорим этот запрос.
Чтобы сохранить исходную таблицу и результаты, мы создадим новую таблицу и скопируем данные с помощью INSERT INTO SELECT:
Чтобы добавить проекцию, мы используем оператор ALTER TABLE вместе с оператором ADD PROJECTION:
После добавления проекции необходимо выполнить оператор MATERIALIZE PROJECTION,
чтобы данные в ней были физически упорядочены и перезаписаны
в соответствии с указанным выше запросом:
Теперь, когда мы добавили проекцию, давайте снова выполним запрос:
Обратите внимание, что нам удалось существенно сократить время выполнения запроса и при этом сканировать меньше строк.
Мы можем подтвердить, что приведённый выше запрос действительно использовал созданную нами проекцию, обратившись к таблице system.query_log:
Использование проекций для ускорения запросов к данным UK Price Paid
Чтобы продемонстрировать, как проекции могут использоваться для ускорения выполнения запросов, рассмотрим пример с использованием реального набора данных. В этом примере мы будем использовать таблицу из нашего руководства UK Property Price Paid с 30,03 миллионами строк. Этот набор данных также доступен в нашей среде sql.clickhouse.com.
Если вы хотите посмотреть, как была создана таблица и как в неё были вставлены данные, вы можете обратиться к разделу «The UK property prices dataset».
Мы можем выполнить два простых запроса к этому набору данных. Первый выводит список графств Лондона, в которых были заплачены самые высокие цены, а второй вычисляет среднюю цену по этим графствам:
Обратите внимание, что, несмотря на очень высокую скорость выполнения, для обоих запросов был выполнен полный скан всей таблицы с 30,03 миллионами строк из‑за того, что ни town, ни price не были указаны в нашем операторе ORDER BY при создании таблицы:
Давайте посмотрим, удастся ли нам ускорить выполнение этого запроса с помощью проекций.
Чтобы сохранить исходную таблицу и результаты, мы создадим новую таблицу и скопируем данные с помощью оператора INSERT INTO SELECT:
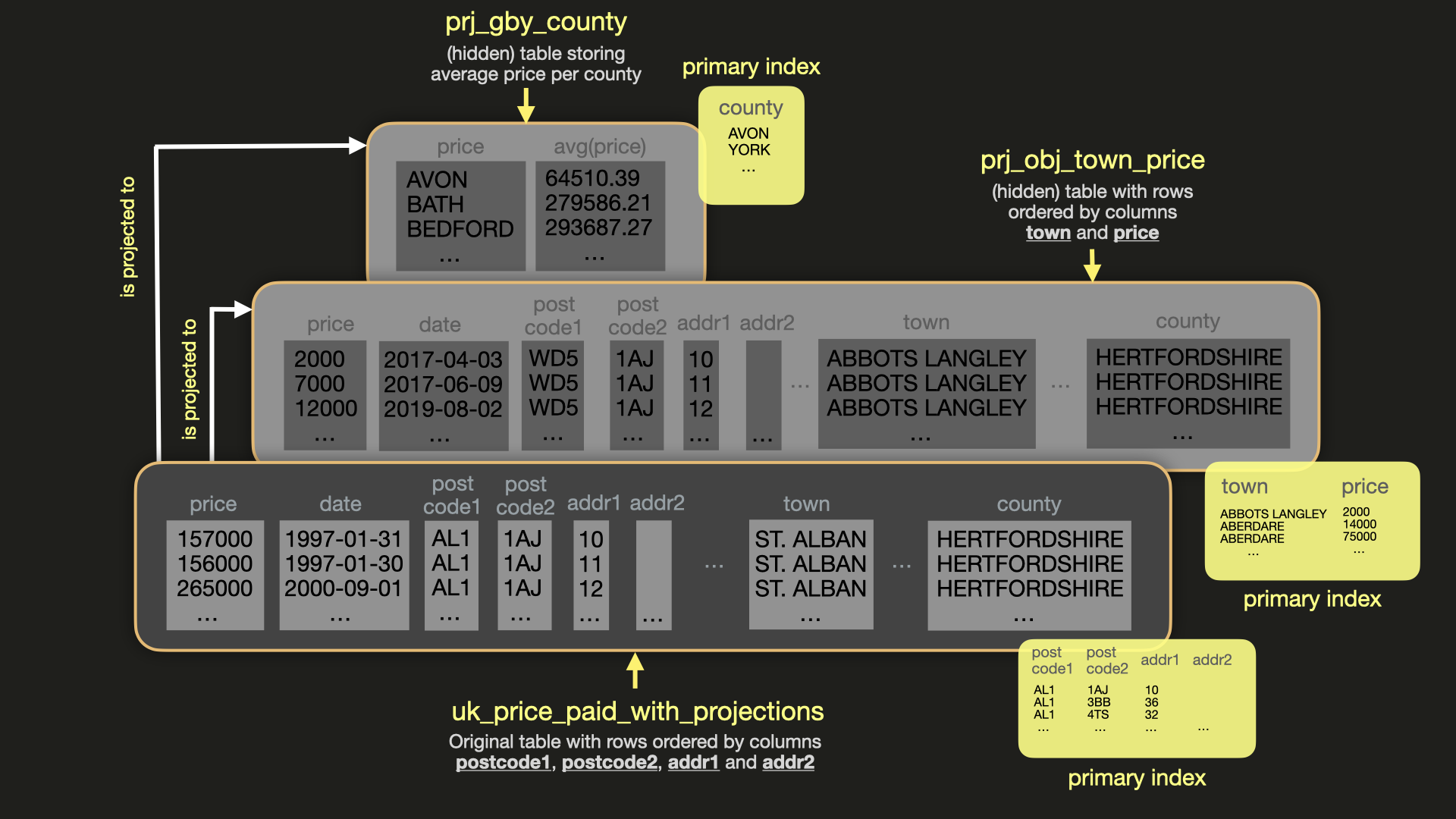
Мы создаём и заполняем проекцию prj_oby_town_price, которая создаёт
дополнительную (скрытую) таблицу с первичным индексом и сортировкой по городу и цене,
чтобы оптимизировать запрос, возвращающий графства в конкретном городе по наивысшим ценам:
Параметр mutations_sync
используется для принудительного синхронного выполнения.
Мы создаём и заполняем проекцию prj_gby_county — дополнительную (скрытую) таблицу,
которая инкрементально предварительно вычисляет агрегатные значения avg(price) для всех 130 существующих
графств Великобритании:
Если в проекции, как в prj_gby_county выше, используется предложение GROUP BY,
то базовым движком хранения для (скрытой) таблицы становится AggregatingMergeTree,
а все агрегатные функции преобразуются в AggregateFunction. Это обеспечивает
корректную инкрементальную агрегацию данных.
Рисунок ниже представляет собой визуализацию основной таблицы uk_price_paid_with_projections
и её двух проекций:
Если теперь снова выполнить запрос, который выводит округа Лондона с тремя наибольшими ценами покупки, мы увидим улучшение производительности запроса:
Аналогично для запроса, выводящего графства Великобритании с тремя наибольшими средними ценами покупки:
Обратите внимание, что оба запроса обращаются к исходной таблице и что оба запроса привели к полному сканированию таблицы (все 30,03 миллиона строк были прочитаны с диска) до того, как мы создали две проекции.
Также обратите внимание, что запрос, который перечисляет графства в Лондоне по трём самым высоким ценам продажи, считывает (стримит) 2,17 миллиона строк. Когда мы напрямую использовали вторую таблицу, специально оптимизированную под этот запрос, с диска было прочитано всего 81,92 тысячи строк.
Причина этой разницы в том, что в данный момент оптимизация
optimize_read_in_order, упомянутая выше, не поддерживается для проекций.
Мы проверяем таблицу system.query_log, чтобы увидеть, что ClickHouse
автоматически использовал две проекции для двух приведённых выше запросов
(см. столбец projections ниже):
Дополнительные примеры
В следующих примерах используется тот же набор данных по ценам в Великобритании, чтобы сравнить запросы с проекциями и без них.
Чтобы сохранить нашу исходную таблицу (и производительность), мы снова создаём копию таблицы с помощью CREATE AS и INSERT INTO SELECT.
Создание проекции
Создадим агрегирующую проекцию по измерениям toYear(date), district и town:
Заполните проекцию для существующих данных. (Если не выполнять материализацию, проекция будет создаваться только для вновь вставляемых данных):
Следующие запросы сравнивают производительность с проекциями и без них. Для отключения использования проекций используется настройка optimize_use_projections, которая включена по умолчанию.
Запрос 1. Средняя цена по годам
Результаты должны совпадать, но во втором примере производительность будет лучше!
Запрос 2. Средняя цена по годам для Лондона
Запрос 3. Самые дорогие районы
Условие (date >= '2020-01-01') необходимо изменить так, чтобы оно соответствовало измерению проекции (toYear(date) >= 2020):
Снова результат тот же, но обратите внимание на улучшение производительности второго запроса.
Комбинирование проекций в одном запросе
Начиная с версии 25.6, на основе поддержки _part_offset,
появившейся в предыдущей версии, ClickHouse теперь может использовать несколько
проекций для ускорения одного запроса с несколькими фильтрами.
Важно, что ClickHouse по-прежнему читает данные только из одной проекции (или базовой таблицы), но может использовать первичные индексы других проекций, чтобы отбросить ненужные парты до чтения. Это особенно полезно для запросов, фильтрующих по нескольким столбцам, каждый из которых может соответствовать своей проекции.
В настоящее время этот механизм позволяет отбрасывать только целые парты. Фильтрация на уровне гранул пока не поддерживается.
Чтобы продемонстрировать это, мы определим таблицу (с проекциями, использующими столбцы _part_offset)
и вставим пять примерных строк, соответствующих диаграммам выше.
Затем вставим данные в таблицу:
Примечание: в таблице используются специальные настройки для иллюстрации, например гранулы размером в одну строку и отключённые слияния частей данных, что не рекомендуется для использования в продакшене.
Эта конфигурация приводит к следующему:
- Пяти отдельным частям (по одной на каждую вставленную строку)
- По одной записи в первичном индексе на строку (в базовой таблице и в каждой проекции)
- Каждая часть содержит ровно одну строку
С такой конфигурацией мы выполняем запрос с фильтрацией сразу по region и user_id.
Поскольку первичный индекс базовой таблицы построен по event_date и id, он
здесь бесполезен, поэтому ClickHouse использует:
region_projдля отсечения частей по регионуuser_id_projдля дополнительного отсечения поuser_id
Это поведение видно с помощью EXPLAIN projections = 1, который показывает,
как ClickHouse выбирает и применяет проекции.
Вывод EXPLAIN (показан выше) показывает логический план запроса сверху вниз:
| Row number | Description |
|---|---|
| 3 | План чтения из базовой таблицы page_views |
| 5-13 | Использует region_proj, чтобы определить 3 части, где region = 'us_west', отсекая 2 из 5 частей |
| 14-22 | Использует user_id_proj, чтобы определить 1 часть, где user_id = 107, дополнительно отсекая 2 из 3 оставшихся частей |
В итоге из базовой таблицы читается только 1 часть из 5. Комбинируя анализ индексов нескольких проекций, ClickHouse значительно сокращает объём сканируемых данных, повышая производительность при низких накладных расходах на хранение.
